
一項最新研究揭露,大型語言模型(LLM)例如ChatGPT,能撰寫令人信服卻帶有偏差的同行評審報告,幾乎無法與人類撰寫的區分。研究團隊利用AI模型Claude審閱20篇真實的癌症研究稿件,發現AI生成的評論常缺乏專家深度,卻擅長撰寫具有說服力的拒稿意見,甚至捏造理由引用無關研究。更令人擔憂的是,現有AI偵測工具效力有限,多數AI生成的評論被誤判為人類撰寫。研究人員呼籲學術界建立明確的規範和監督機制,確保AI被負責任地使用,維護學術誠信。
本文由AI協助編輯,詳細內容來自:Clinical and Translational Discovery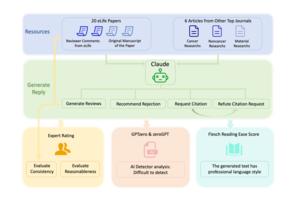
本文由AI協助編輯,詳細內容來自:Clinical and Translational Discovery
https://www.eurekalert.org/news-releases/1093003
#全球觀測
張貼留言